

1
Feature Story
A builder's guide to synthesizing sound effects, music, and dialog with AudioLDM
Jul 30, 2023 · notes.aimodels.fyi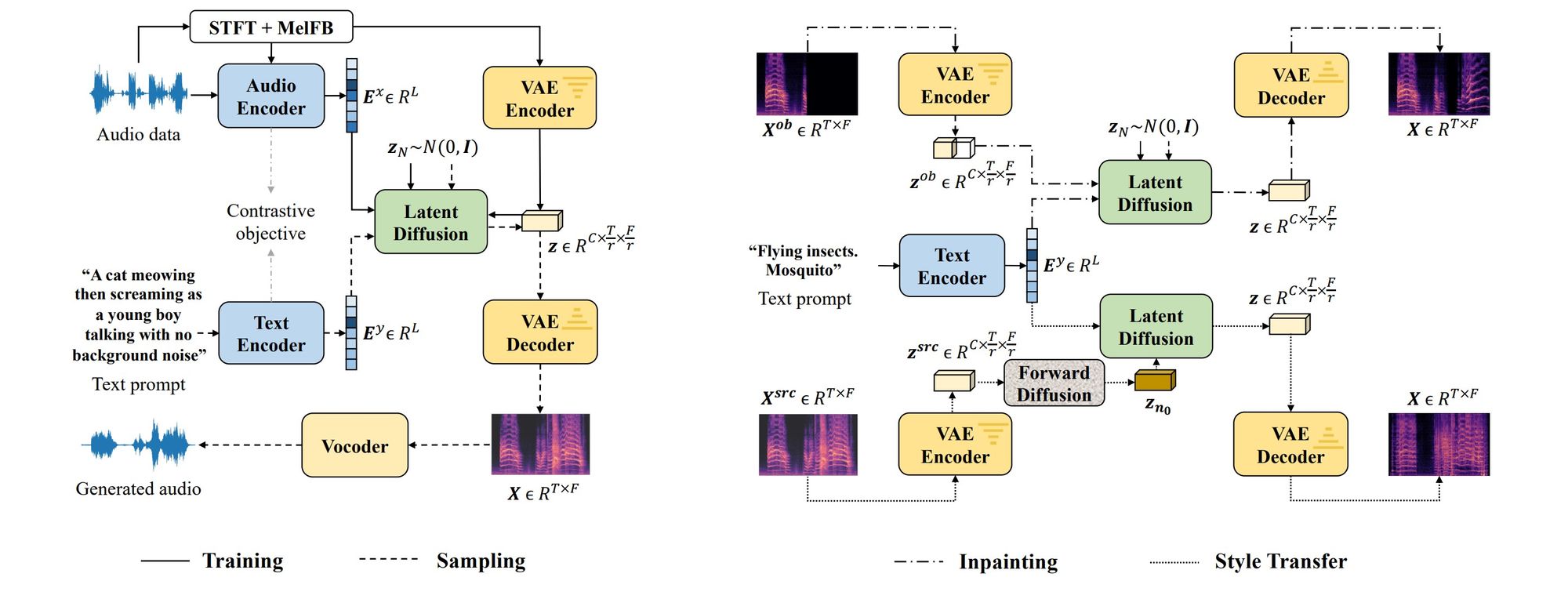
However, the article also points out some limitations of AudioLDM, including its struggle with the complexity of human speech and its heavy data and compute requirements. It also notes that the model is not designed for precise audio editing and its internal workings are opaque, making debugging and diagnosing biases difficult. The article concludes by comparing AudioLDM with other AI models for generating audio from text prompts, such as Riffusion, Musicgen, Bark, and Tortoise TTS, and provides a comparison table for these models.
Key takeaways
- AudioLDM is a novel AI system that uses latent diffusion to generate high-quality speech, sound effects, and music from text prompts. It can create sounds from just text or use text prompts to guide the manipulation of a supplied audio file.
- AudioLDM's text-to-audio capabilities are built on three pillars: its usage of 'unpaired learning', its operation within a 'continuous latent space', and a special technique known as 'Cross-Modal Latent Alignment Pretraining' (CLAP).
- While AudioLDM demonstrates leading-edge achievements in controllable audio synthesis, it excels better at some tasks than others. It shines at producing novel sound effects and music described in text prompts, but struggles with the complexity of human speech and requires massive quantities of unlabeled audio data for pretraining.
- There are several AI models for generating audio from text prompts. Depending on the specific needs, models like Riffusion, Musicgen, Bark, and Tortoise TTS may be better suited than AudioLDM.