

1
Feature Story
AI leaderboards are no longer useful. It's time to switch to Pareto curves.
Apr 30, 2024 · aisnakeoil.com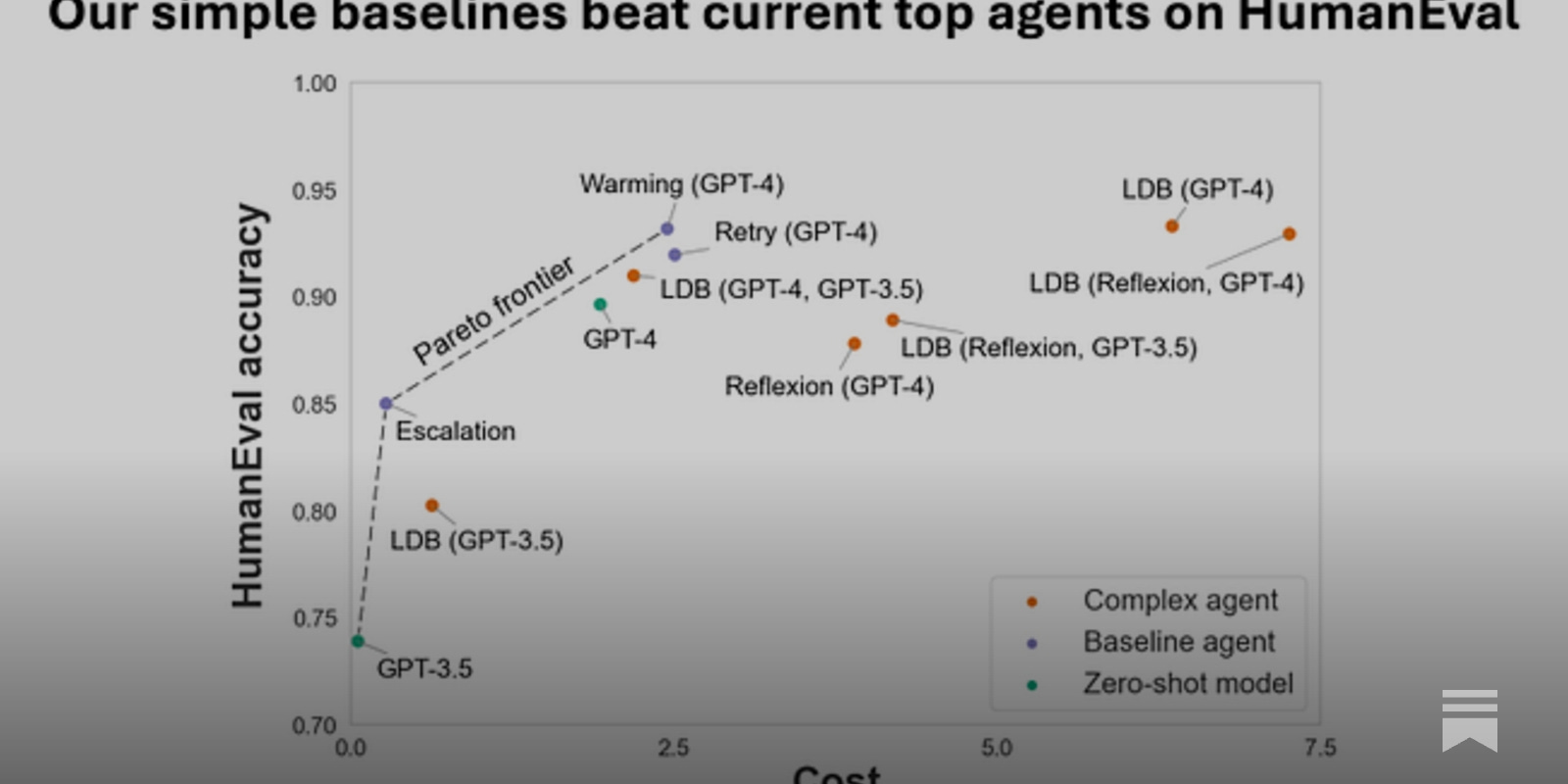
The authors also critique the use of proxies such as parameter count for cost, arguing that they can be misleading and that dollar costs should be directly measured. They distinguish between model evaluation, which is of interest to researchers, and downstream evaluation, which is of interest to developers using AI in their products. The authors also note several issues with the reproducibility and standardization of agent evaluations, including discrepancies in reported results and the use of different subsets of benchmarks. They conclude by advocating for the visualization of cost and accuracy as a Pareto curve and the evaluation of agents on custom datasets.
Key takeaways
- The most accurate AI system for generating code, based on HumanEval, is LDB (short for LLM debugger). However, these systems can be costly to run.
- AI agent accuracy measurements that don’t control for cost aren’t useful. Pareto curves can help visualize the accuracy-cost tradeoff.
- Current state-of-the-art agent architectures are complex and costly but no more accurate than extremely simple baseline agents that cost 50x less in some cases.
- There are many shortcomings in the reproducibility and standardization of agent evaluations, leading to overoptimism about agents in the broader AI community.