

1
Feature Story
AI scaling myths
Jun 28, 2024 · aisnakeoil.com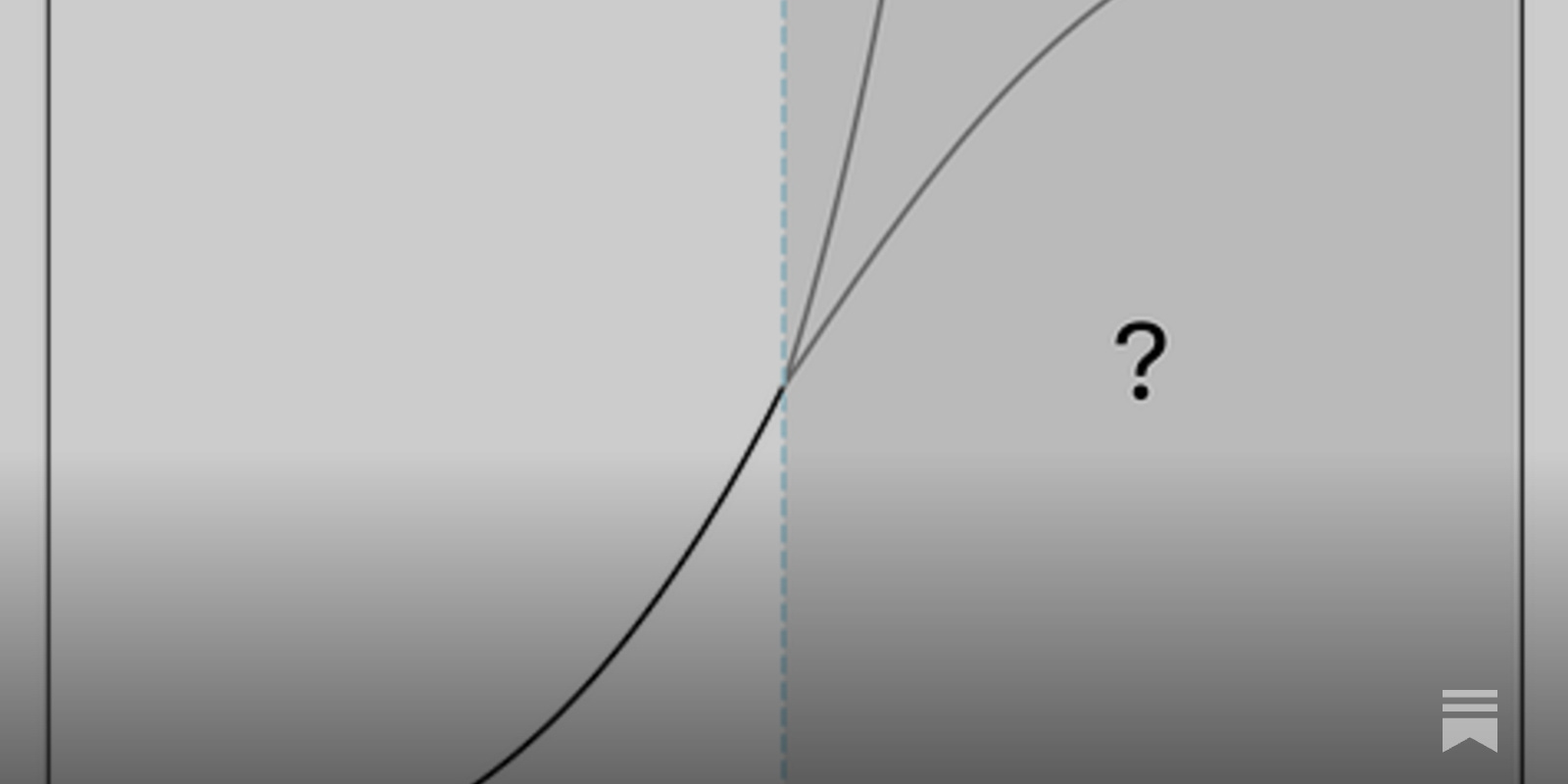
The authors further discuss how the focus in AI research has shifted from compiling larger datasets to improving the quality of training data. They also note that the trend of building bigger models is not a wise business move as capability is no longer the barrier to adoption. Instead, much effort is being put into producing smaller, more efficient models. They conclude by stating that the AI research community has historically been poor at predicting the future of AI and that it is a trend likely to continue.
Key takeaways
- The article argues that scaling alone will not lead to artificial general intelligence (AGI), and the belief that it will is based on misconceptions about scaling laws.
- Language model developers are already at the limit of high-quality training data, and the industry is seeing strong downward pressure on model size.
- While synthetic data is often suggested as a path to continued scaling, the authors believe this rests on a misconception and that it's unlikely that synthetic training data will have the same effect as having more high-quality human data.
- Despite the trend of scaling in dataset size, model size, and training compute, the authors argue that capability is no longer the barrier to adoption, and that cost and other factors are preventing the adoption of applications that could be built with current language model capabilities.