

1
Feature Story
Alex Strick van Linschoten - My finetuned models beat OpenAI’s GPT-4
Jul 01, 2024 · mlops.systems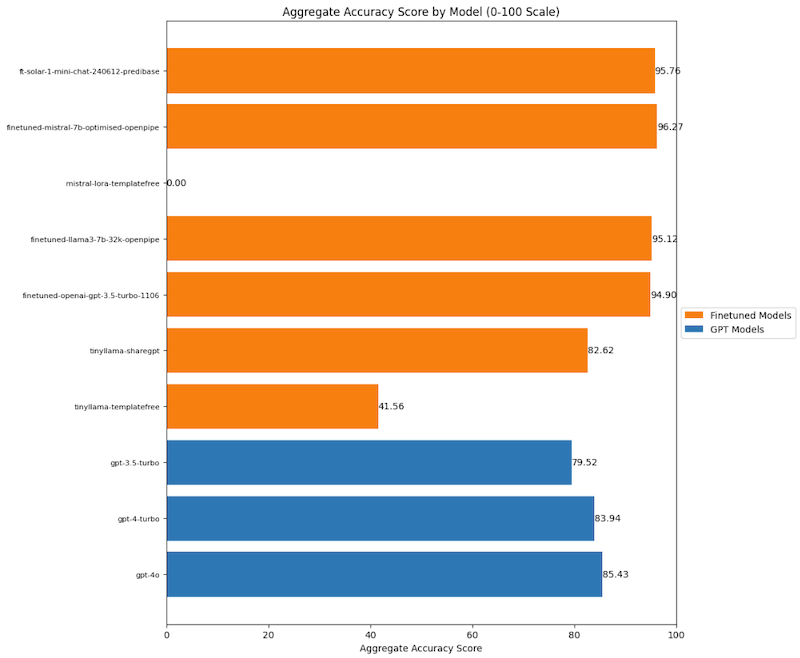
The author then uses OpenAI to make predictions and stores these predictions on the Pydantic object. The author also discusses the challenges of rate limiting on the GPT-3.5-turbo model and how to handle it. The author then converts the list of Pydantic objects to a Hugging Face Dataset object and pushes it to the Hugging Face Hub. The author concludes by discussing the addition of predictions from finetuned models, including a mix of local models and models hosted by one-click finetuning providers.
Key takeaways
- The author is evaluating the performance of their finetuned Language Learning Model (LLM) in extracting structured data from press releases.
- The core metric of interest is accuracy, but other evaluation metrics will also be considered.
- The author uses the Hugging Face Hub to load datasets and uses Python code to load and process the data, make predictions, and store the results.
- The author also discusses the challenges of comparing the accuracy of finetuned models with GPT models, given the different prompts they require.