

1
Feature Story
Build a chatbot with custom data sources, powered by LlamaIndex
Aug 24, 2023 · blog.streamlit.io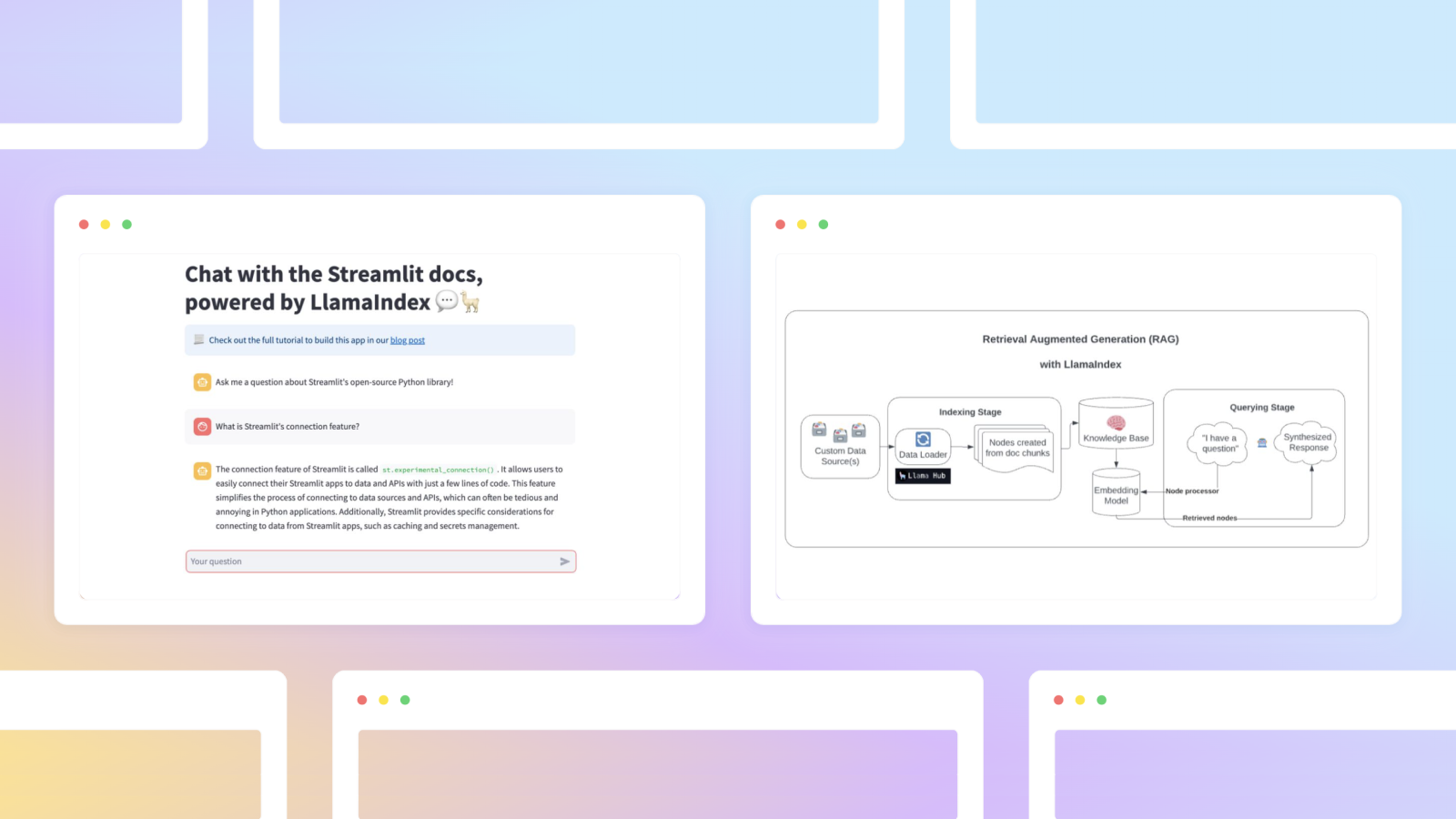
The tutorial demonstrates how to build a chatbot in 43 lines of code, using LlamaIndex to load and index data, create a chat UI with Streamlit's methods, store and update the chatbot's message history, and augment GPT-3.5 with the loaded, indexed data. The article emphasizes that LlamaIndex can be used to enrich models with contextual data and construct RAG pipelines, making it accessible to developers of all experience levels. It also highlights the benefits of using LlamaIndex, such as preventing hallucinations and ensuring higher accuracy of responses.
Key takeaways
- LlamaIndex is a framework that allows LLM applications to ingest, structure, access, and retrieve private data sources, enhancing the model's responses to be more relevant and context-specific.
- The post provides a step-by-step guide on how to build a chatbot using LlamaIndex to augment GPT-3.5 with Streamlit documentation in just 43 lines of code.
- LlamaIndex works through a two-stage process: an indexing stage where it prepares the knowledge base by ingesting data and converting it into Documents, and a querying stage where relevant context is retrieved from the knowledge base to assist the model in responding to queries.
- Using LlamaIndex to augment LLMs like GPT-3.5 can result in more accurate and up-to-date responses, especially when dealing with domain-specific or recent data.