

1
Feature Story
Consistency Large Language Models: A Family of Efficient Parallel Decoders
May 08, 2024 · hao-ai-lab.github.io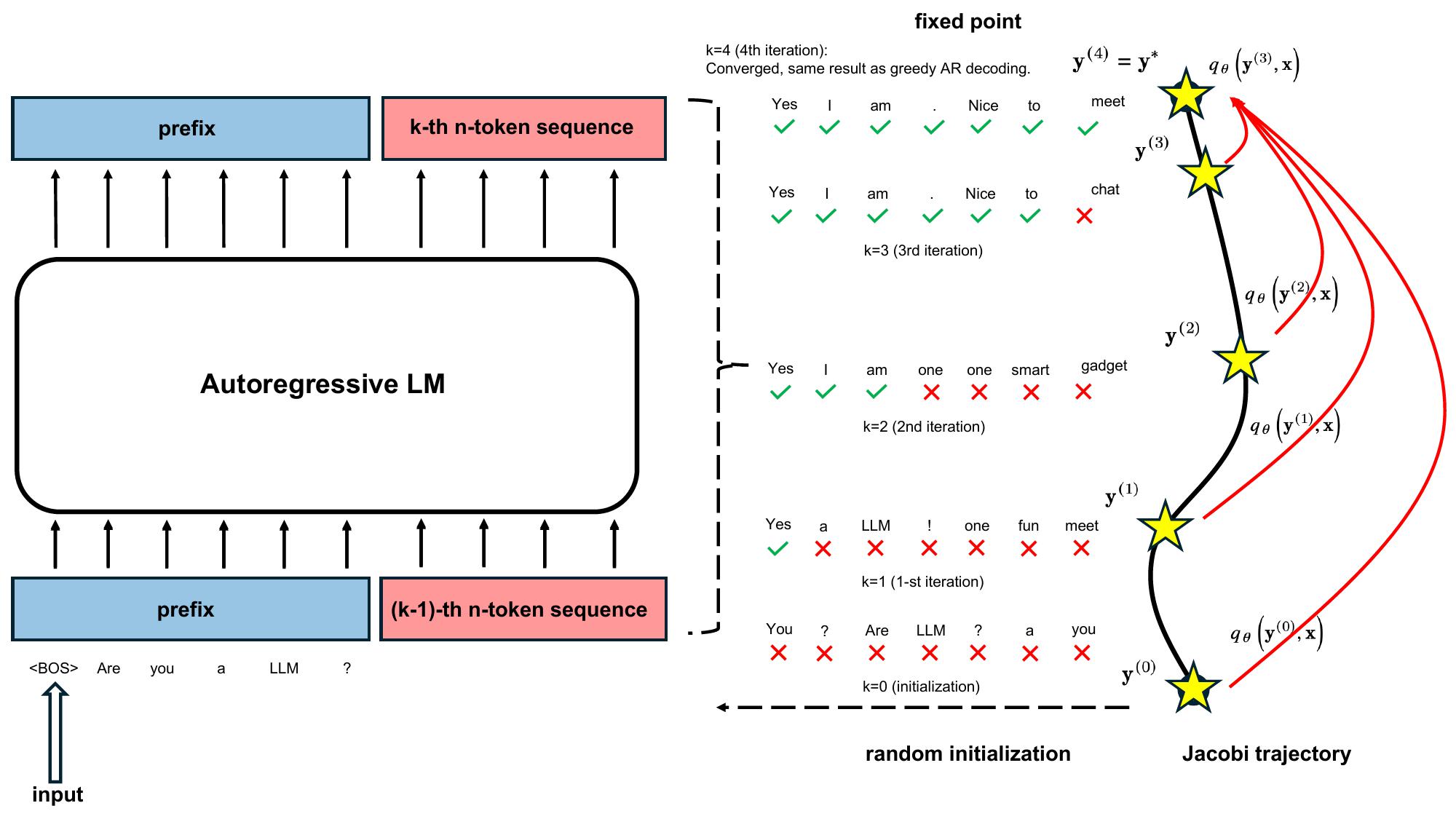
The experiments conducted showed that CLLMs obtained using the proposed method are highly effective, showing 2.4x to 3.4x improvements in generation speed, in par with or even better than other fast inference techniques like Medusa2 and Eagle, yet require no additional memory cost to accommodate auxiliary model components at inference time. The article also discusses the training cost of CLLMs, the fast forwarding and stationary tokens phenomena, and the concept of collocations that CLLMs acquire through training.
Key takeaways
- The article introduces Consistency Large Language Models (CLLMs), a new family of parallel decoders that can reduce inference latency by efficiently decoding an n-token sequence per inference step.
- CLLMs are trained to perform parallel decoding by mapping any randomly initialized n-token sequence to the same result yielded by autoregressive (AR) decoding in as few steps as possible.
- Experiments show that CLLMs are highly effective, showing 2.4x to 3.4x improvements in generation speed, in par with or even better than other fast inference techniques like Medusa2 and Eagle, yet require no additional memory cost to accommodate auxiliary model components at inference time.
- The fine-tuning cost of CLLMs is moderate, e.g., passing only around 1M tokens for LLaMA-7B to achieve a 3.4x speedup on the Spider dataset.