

1
Feature Story
Decoding Speech from Brain Waves - A Breakthrough in Brain-Computer Interfaces
Oct 06, 2023 · notes.aimodels.fyi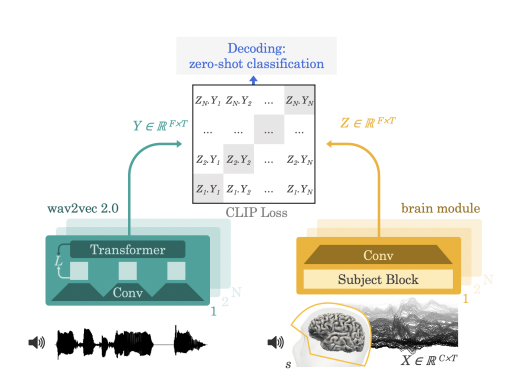
The model achieved up to 73% accuracy for MEG recordings and 19% for EEG recordings when identifying 3-second segments of speech from over 1,500 possibilities. This represents a significant improvement over previous attempts at speech decoding using non-invasive sensors. However, the current accuracy is still too low for natural conversations, and further research is needed to improve the model's performance and to ensure its accuracy when participants are speaking or imagining speaking. Despite these challenges, this study represents a major milestone in the field of neuroscience and artificial intelligence.
Key takeaways
- A recent study has used a deep learning model to decode speech directly from non-invasive brain recordings, potentially paving the way for restoring communication abilities in patients with speech loss due to neurological conditions.
- The model was trained to predict representations of the speech audio from the corresponding brain activity patterns, using a contrastive loss function, pretrained speech representations, and a convolutional neural network.
- The model achieved up to 73% accuracy for MEG recordings and 19% accuracy for EEG recordings, a significant improvement over previous attempts at speech decoding using non-invasive sensors.
- While promising, the technology still faces challenges, including the need for higher accuracy for natural conversations, the difference in brain signals during active speech production versus passive listening, and susceptibility to interference from muscle movements and other artifacts.