

1
Feature Story
fast.ai - Can LLMs learn from a single example?
Sep 06, 2023 · fast.ai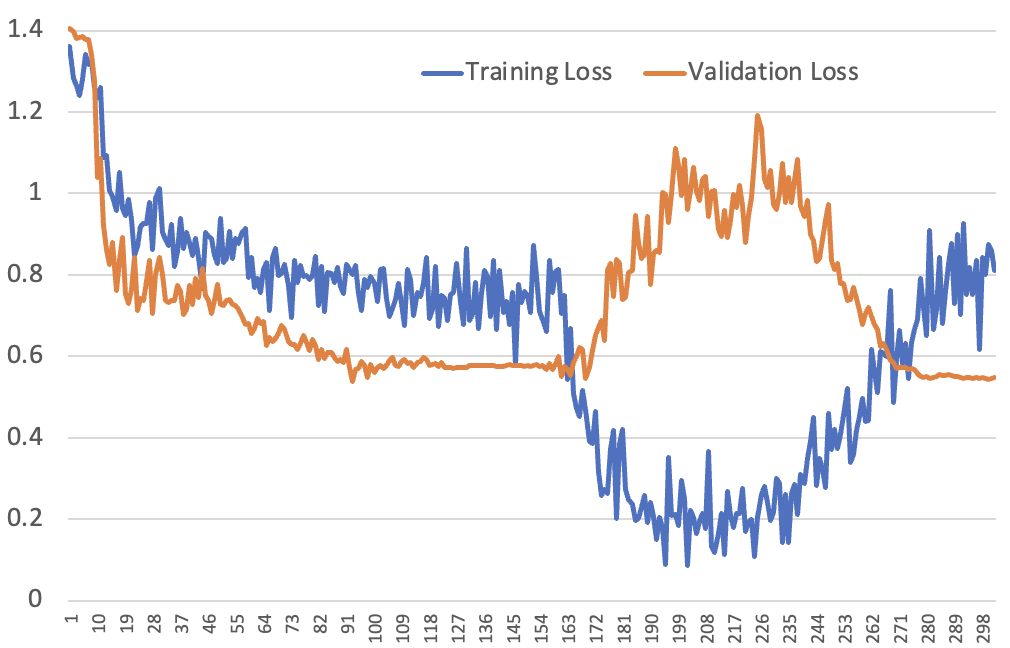
The authors also speculate on why this might be the case, suggesting that pre-trained LLMs might have extremely smooth loss surfaces in areas close to minimal loss, allowing for rapid learning. They also discuss the potential implications of this rapid learning, such as the increased prominence of the catastrophic forgetting problem and the potential decreased usefulness of data augmentation. They suggest potential mitigation strategies, such as increased use of techniques like dropout or stochastic depth, or using rich mixtures of datasets throughout training.
Key takeaways
- While fine-tuning a large language model (LLM) on multiple-choice science exam questions, researchers observed unusual training loss curves, suggesting the model was able to rapidly memorize examples from the dataset after seeing them just once, contradicting prior wisdom about neural network sample efficiency.
- Experiments conducted to understand this phenomenon supported the hypothesis that the models are able to rapidly remember inputs, which might mean a need to re-think how LLMs are trained and used.
- The researchers suggest that pre-trained large language models may have extremely smooth loss surfaces in areas close to the minimal loss, and that a lot of the fine-tuning work done in the open source community is in this area.
- This rapid learning could potentially turn basic ideas about how to train models on their head, possibly making data augmentation less useful for avoiding over-fitting and increasing the risk of catastrophic forgetting. The researchers suggest potential mitigations such as increasing the use of techniques like dropout or stochastic depth, or using rich mixtures of datasets throughout training.