

1
Feature Story
Fuyu-8B: A Multimodal Architecture for AI Agents
Oct 18, 2023 · adept.ai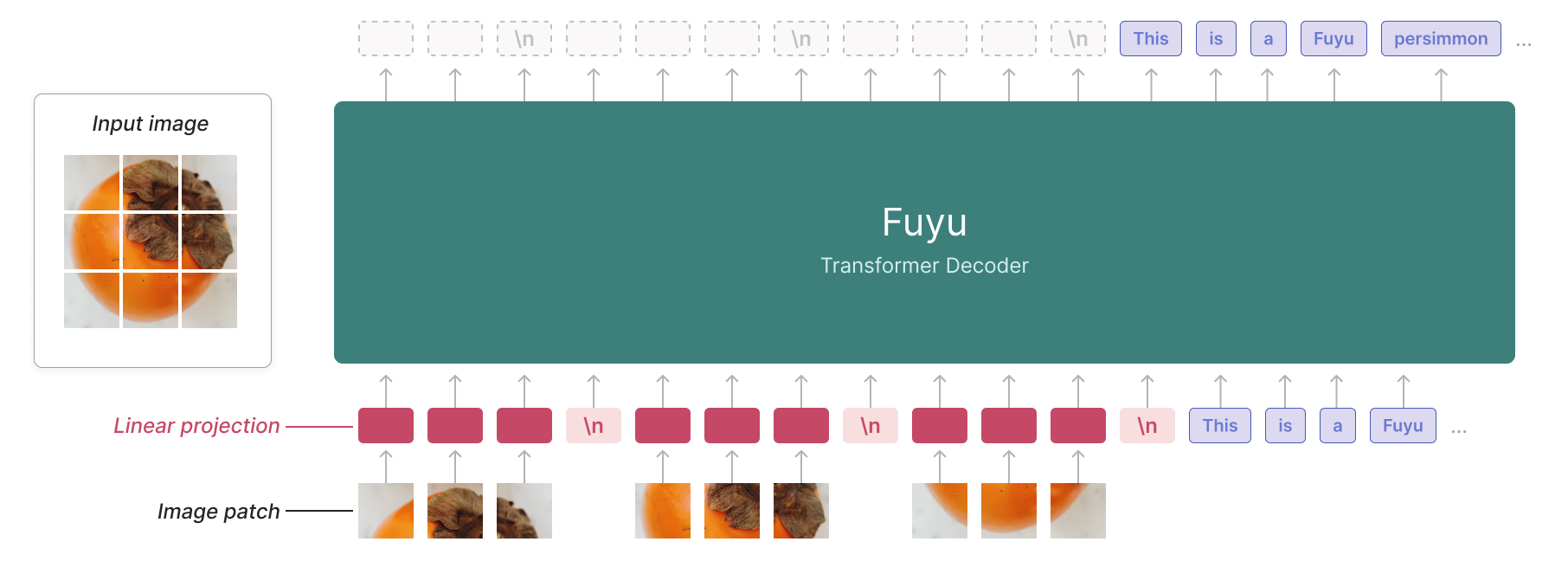
Fuyu-8B has a simpler architecture and training procedure than other multi-modal models, making it easier to understand, scale, and deploy. It can understand complex visual relationships, answer nontrivial, multi-hop questions given traditional charts, and understand documents — both complex infographics and old PDFs. The model can also understand complex relational queries about scientific diagrams. Adept's internal models, based on Fuyu, have extra capabilities related to their product, including OCR on high-resolution images, fine-grained localization of text and UI elements within those images, and answering questions about images of UIs.
Key takeaways
- The Fuyu-8B model, a smaller version of the multimodal model that powers Adept's product, is now available on HuggingFace.
- Fuyu-8B has a simpler architecture and training procedure than other multimodal models, making it easier to understand, scale, and deploy.
- The model is designed for digital agents, supporting arbitrary image resolutions, answering questions about graphs and diagrams, UI-based questions, and performing fine-grained localization on screen images.
- Fuyu-8B performs well on standard image understanding benchmarks such as visual question-answering and natural-image-captioning, despite being optimized for Adept's specific use-case.