

1
Feature Story
GPT-4o takes #1 & #2 on the Aider LLM leaderboards
May 14, 2024 · aider.chat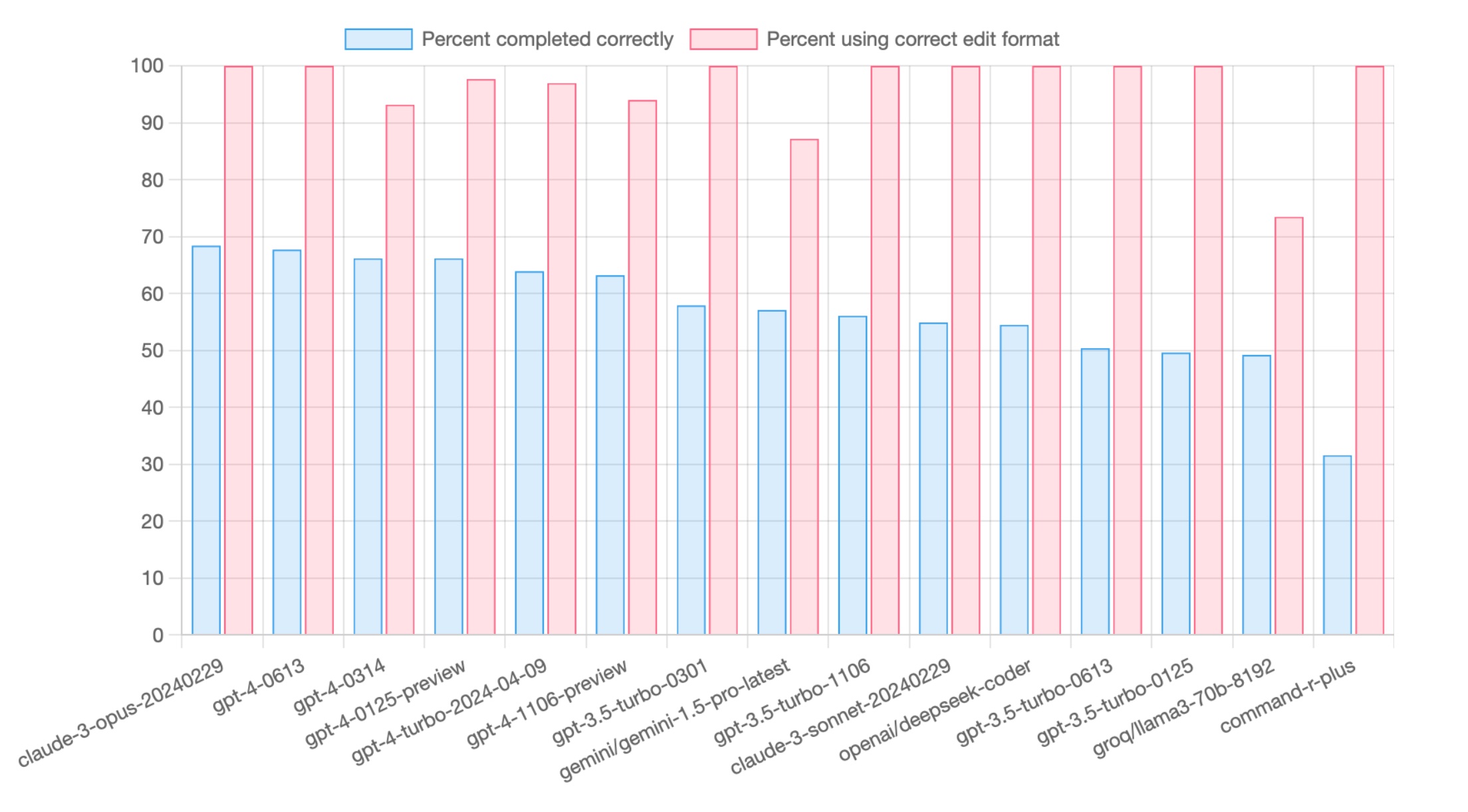
The article further explains the benchmarks used to evaluate the LLMs. The "Percent completed correctly" measures the percentage of coding tasks that the LLM completed successfully, while the "Percent using correct edit format" measures the compliance of the LLM with the edit format specified in the system prompt. The article invites contributions of benchmark results and provides information on how to run Aider’s code editing benchmarks.
Key takeaways
- Aider works best with Language Learning Models (LLMs) that are good at editing code, not just writing it.
- GPT-4o tops the aider LLM code editing leaderboard at 72.9%, and takes second on aider’s refactoring leaderboard with 62.9%.
- Aider uses different 'edit formats' to collect code edits from different LLMs. Models that use a diff-like format are able to edit larger files with less cost and without hitting token limits.
- Contributions of benchmark results are welcome and can be submitted by opening a PR with edits to the benchmark results data files.