

1
Feature Story
How To Solve LLM Hallucinations
Jun 14, 2024 · morethanmoore.substack.com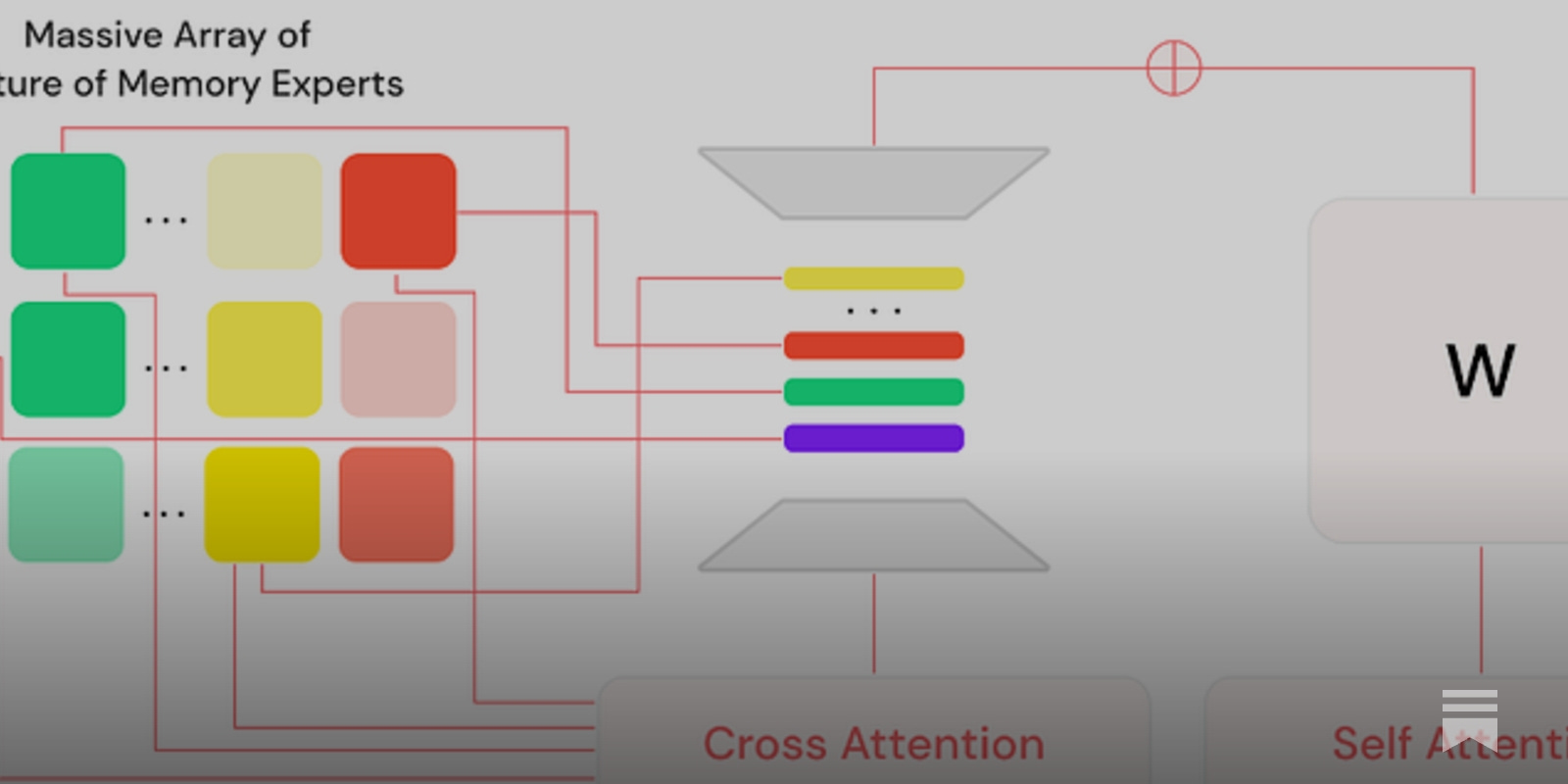
Lamini's Memory Tuning/MoME capability has already been implemented by several customers, including a Fortune 500 company, which has experienced a tenfold reduction in hallucinations in text-to-SQL code generation. The company's approach could potentially redefine the future of machine learning compute profiles, similar to the impact of transformers on convolutional neural networks. However, further research is needed to understand the computational change in the inference and its potential impact on the silicon industry.
Key takeaways
- Lamini, a startup led by CEO Sharon Zhou and CTO Greg Diamos, has developed a new methodology to reduce hallucinations in large language models (LLMs) by 95%.
- The company's approach, called Memory Tuning, involves embedding specific data into models, creating a 'Mixture of Memory Experts' (MoME) that can recall exact data.
- This method could be particularly useful for models dealing with specific knowledge domains, such as a company's product portfolio or support documentation.
- While the computational requirements for Memory Tuning are lower than regular fine-tuning, it is unclear how this method might affect the computational change in inference and whether it could drive a shift in computer architecture.