

1
Feature Story
Llama 3-V: Matching GPT4-V with a 100x smaller model and 500 dollars
May 28, 2024 · aksh-garg.medium.com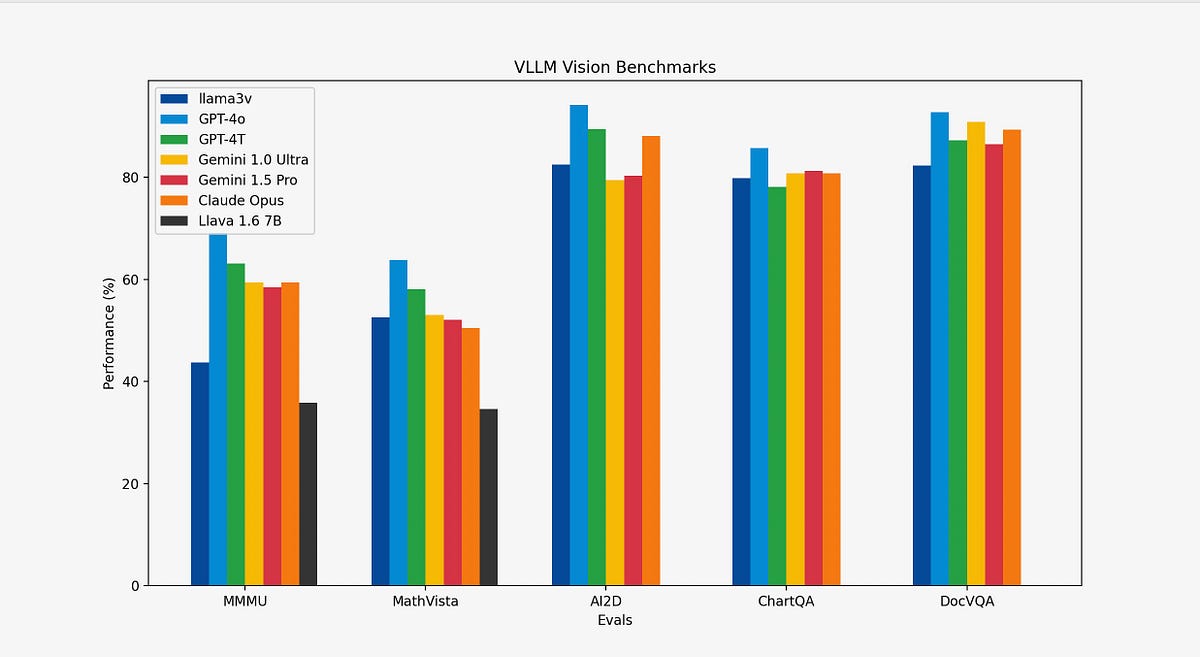
The article also discusses the training framework, system optimizations, and model architecture in detail. To optimize for computation resources, the team used a simple caching mechanism and made optimizations on the MPS/MLX front. The model was trained by precomputing the image embeddings via SigLIP and then learning a projection matrix. After pretraining, supervised finetuning was performed to enhance the model's performance. The article concludes by highlighting that Llama3-V offers comparable vision abilities to models close to 100x larger in size like GPT4v, Gemini Ultra, and Claude Opus.
Key takeaways
- The article introduces Llama3-V, the first-ever multimodal model built on top of Llama3, which outperforms Llava, the current state-of-the-art model for multimodal understanding, by 10-20%.
- Llama3-V uses SigLIP for image embedding and aligns textual and visual tokens using a projection block with two self-attention blocks.
- The training process involves precomputing the image embeddings via SigLIP, learning a projection matrix, and then performing supervised finetuning.
- The model offers comparable vision abilities of models close to 100x larger in size like GPT4v, Gemini Ultra, and Claude Opus, and can be trained in under $500.