

1
Feature Story
LLM Training: RLHF and Its Alternatives
Sep 10, 2023 · magazine.sebastianraschka.com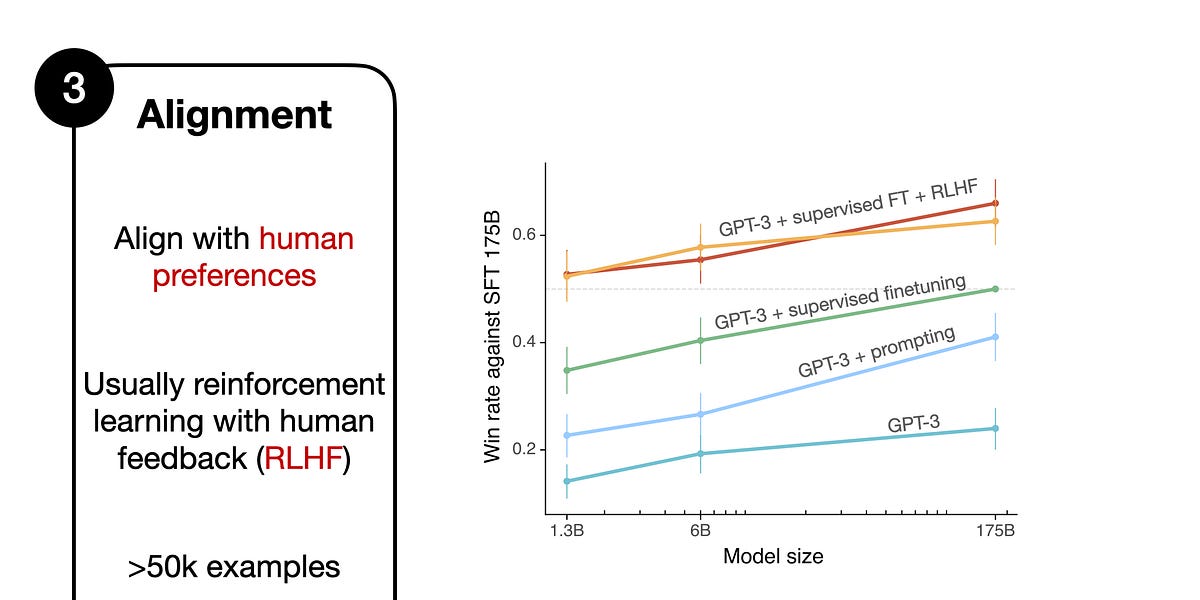
The latter part of the article explores alternatives to RLHF, including Constitutional AI, Hindsight Instruction Labeling (HIR), Direct Preference Optimization (DPO), Reinforced Self-Training (ReST), and Reinforcement Learning with AI Feedback (RLAIF). The author notes that while these alternatives show promise, there is currently no true competitor to Llama 2 and Code Llama-scale models that have been trained without RLHF.
Key takeaways
- The article provides a detailed explanation of Reinforcement Learning with Human Feedback (RLHF), a process integral to the training of modern Language Learning Models (LLMs) like ChatGPT and Llama 2.
- RLHF involves three steps: supervised finetuning of the pretrained model, creating a reward model, and finetuning via proximal policy optimization. This process helps to align the LLM with human preferences, improving the model's helpfulness and safety.
- The article compares the RLHF methods used in ChatGPT and Llama 2, highlighting differences such as Llama 2's use of two reward models and an added rejection sampling step.
- The article also explores alternatives to RLHF, including Constitutional AI, Hindsight Instruction Labeling (HIR), Direct Preference Optimization (DPO), Reinforced Self-Training (ReST), and Reinforcement Learning with AI Feedback (RLAIF). These alternatives aim to make the training process more efficient and accessible.