

1
Feature Story
LLMs Aren’t “Trained On the Internet” Anymore
Jun 01, 2024 · allenpike.com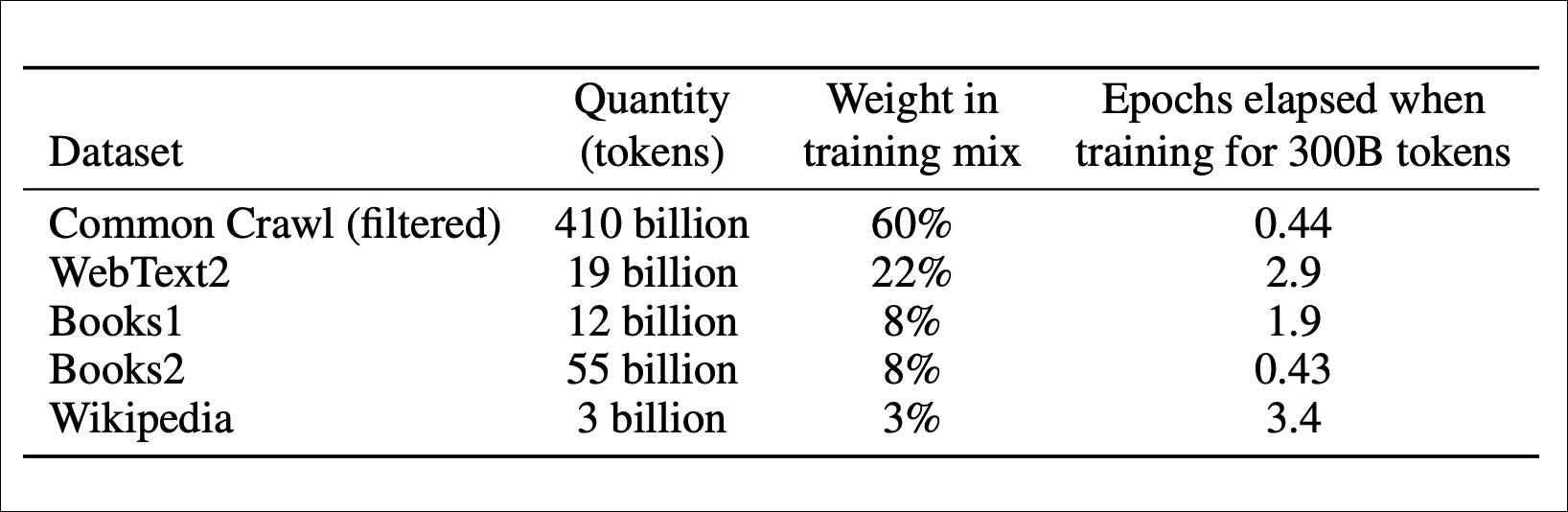
The article also highlights the rise of synthetic data and human-generated data in LLM training. Companies like Scale.ai are being paid to create new data, with AI companies reportedly spending over $1B a year on such services. This trend is expected to help LLMs surpass the "internet simulation" stage and improve their performance in areas not well-represented on the internet.
Key takeaways
- Language Learning Models (LLMs) are no longer solely trained on internet data, but increasingly on custom data, which is changing their capabilities and potential for improvement.
- LLMs are being trained to follow instructions using human feedback and are also being trained on non-public data, which is helping to overcome the 'data wall' problem.
- Custom data, including synthetic data generated by larger LLMs and data created by humans, is becoming a significant factor in improving LLM performance.
- Companies are investing heavily in creating new, high-quality training data, with AI companies reportedly paying over $1B a year for such services, which is expected to lead to LLMs exceeding 'internet simulation' and improving in areas not well represented on the internet.