

1
Feature Story
Meet ALMA: A New Training Method That Boosts Translation Performance for Large Language Models
Sep 23, 2023 · notes.aimodels.fyi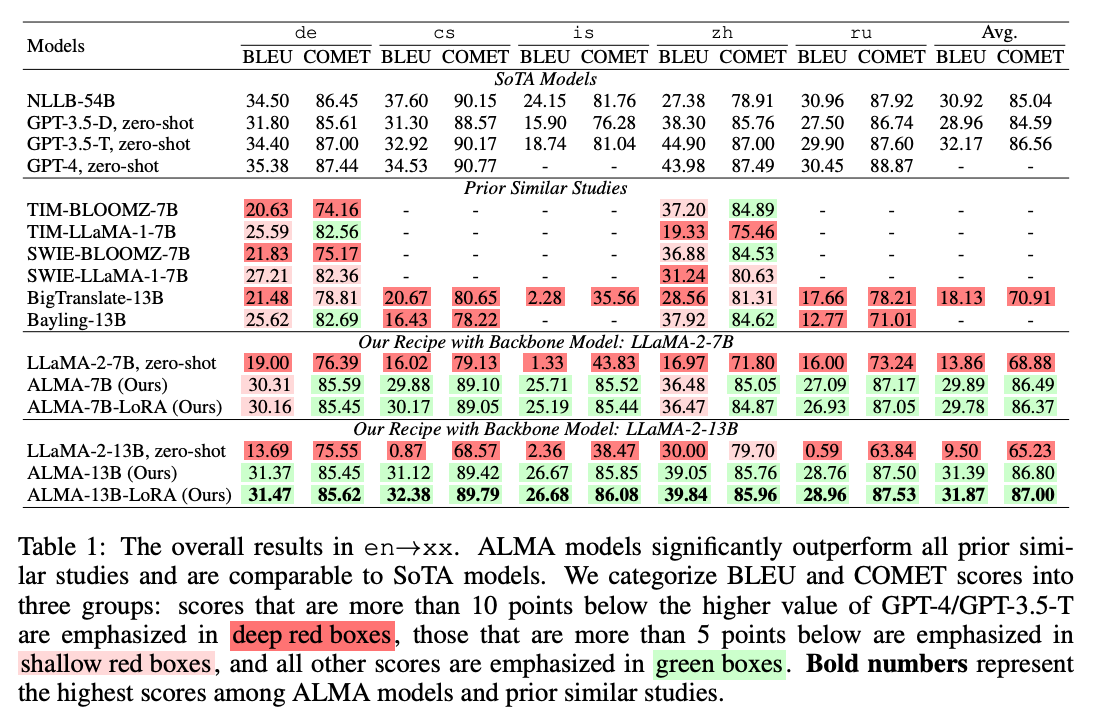
The ALMA models, based on the LLaMA architecture, were tested on 10 language pairs and showed substantial improvement over LLaMA's zero-shot translation. They also outperformed all prior work fine-tuning LLMs for translation and slightly exceeded GPT-3 and NLLB, despite having fewer parameters. This research suggests that the traditional approach of using more data for training may not always be the best strategy, and a more targeted fine-tuning could maximize performance.
Key takeaways
- Researchers from Johns Hopkins University and Microsoft have proposed a new training method that enhances the translation capabilities of smaller large language models (LLMs), enabling them to perform on par with larger models like GPT-3.
- Smaller LLMs, with 7-13 billion parameters, have traditionally underperformed in machine translation tasks compared to traditional encoder-decoder models. The new method involves a two-stage fine-tuning process, focusing on monolingual fine-tuning and high-quality parallel fine-tuning.
- The researchers developed ALMA (Advanced Language Model-based translators) models using this method, which outperformed previous models in translation tasks, even exceeding the performance of GPT-3 and NLLB, despite having fewer parameters.
- This research suggests a shift in the training paradigm for LLMs, moving away from the need for massive parallel text data and towards more specialized fine-tuning. This could lead to more efficient, accessible, and scalable machine translation systems.