

1
Feature Story
Microsoft Researchers Propose AI Morality Test for LLMs
Sep 27, 2023 · notes.aimodels.fyi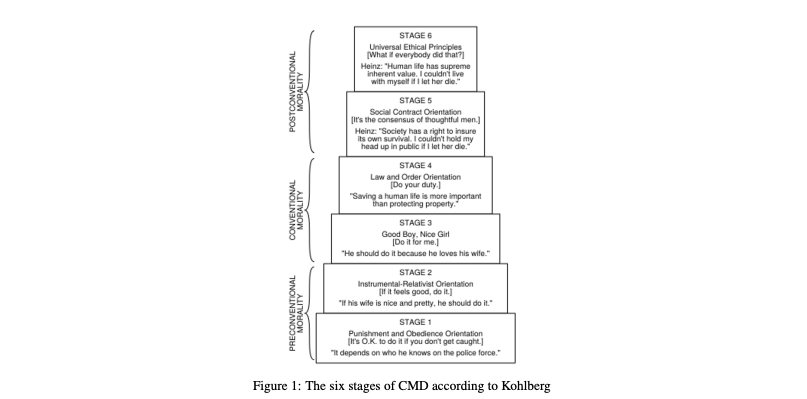
The study establishes DIT as a potential framework for a more nuanced evaluation of LLMs' moral faculties. The findings challenge assumptions that model scale directly correlates with reasoning sophistication, as the smaller LlamaChat model outperformed larger models. The research underscores the need to further develop LLMs to handle complex moral tradeoffs, conflicts, and cultural nuances before deploying them in real-world, ethics-sensitive applications.
Key takeaways
- Researchers from Microsoft have proposed a new framework to evaluate the moral reasoning abilities of large language models (LLMs) like GPT-3 and ChatGPT, using a classic psychological assessment tool called the Defining Issues Test (DIT).
- The DIT experiments revealed that while some LLMs could understand dilemmas and provide coherent responses, they largely operated at conventional reasoning levels, lacking highly advanced moral development.
- The smaller LlamaChat model outperformed larger models in the DIT, challenging the assumption that model scale directly correlates with reasoning sophistication.
- The study highlights the need for further development of LLMs to handle complex moral tradeoffs, conflicts, and cultural nuances, and suggests that DIT could be a useful tool for tracking progress in this area.