

1
Feature Story
New attack needs just API access and $20 to extract GPT-4’s hidden architecture
Mar 13, 2024 · medium.com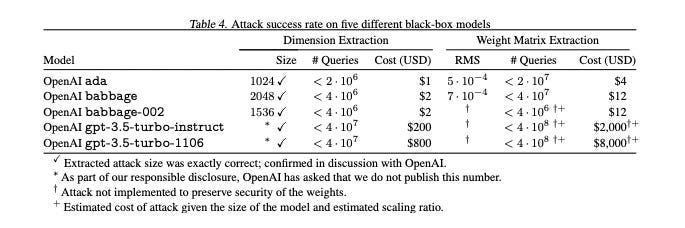
The attack exploits the low-rank structure of the final output layer of common language model architectures. By carefully querying the model, attackers can recover the hidden dimension or even the entire output projection matrix. This development marks a significant advance in model stealing, with potential wide-ranging impacts on the future of AI development.
Key takeaways
- A new model-stealing attack has been discovered that can extract secret parameters from large production language models like GPT-4, PaLM-2, and Claude using only standard API access.
- The attack allows for the extraction of information about a language model’s hidden architecture purely through standard API queries, potentially enabling further attacks.
- The researchers were able to successfully recover the precise hidden dimension size from models by OpenAI, Google, and Anthropic at costs as low as $20.
- The key insight underpinning this model extraction attack is that the final output layer of common language model architectures is low-rank, allowing the attacker to recover the hidden dimension or even the entire output projection matrix.