

1
Feature Story
New LLM Foundation Models
Aug 30, 2023 · magazine.sebastianraschka.com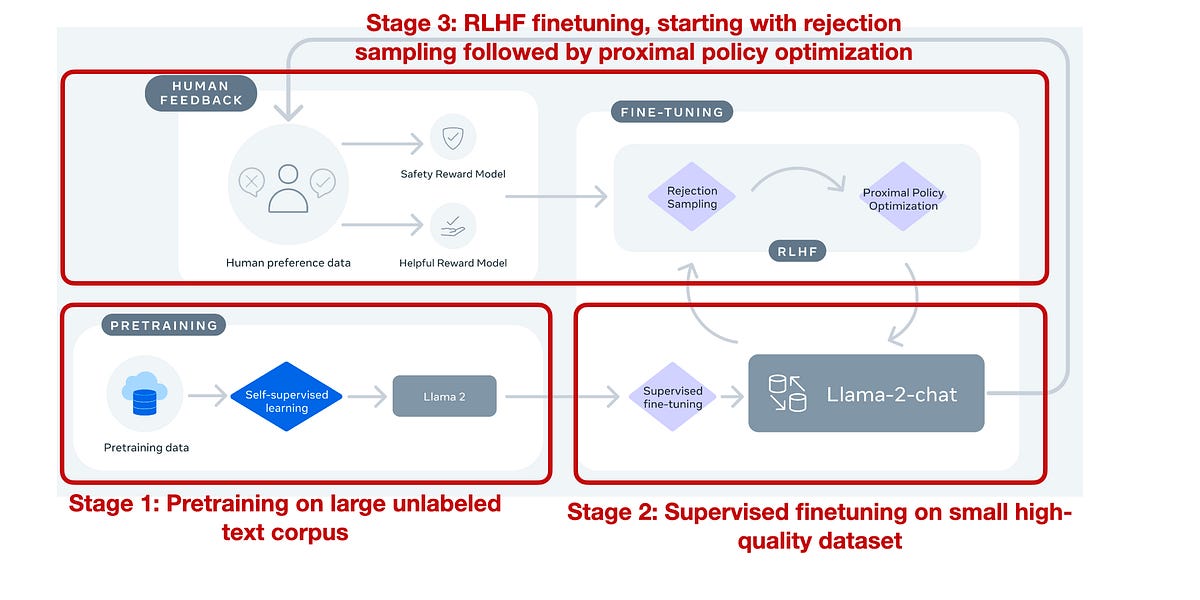
The author also discusses the new finetuning API announced by OpenAI, designed to train the GPT-3.5-turbo on custom data sets. This could potentially fuel ongoing conversations around closed, proprietary AI systems and open-source AI models. The article further explores the potential of Llama 2, its licensing and usage restrictions, and its performance compared to other models. The author also touches upon the ongoing GPU shortage and the legal implications of using copyrighted materials for training AI models.
Key takeaways
- The article discusses the release of Llama 2, an open-source AI large language model (LLM) that has been trained on 40% more data than its predecessor and supports larger inputs. It also includes finetuned models and allows for commercial use.
- OpenAI has announced a new finetuning API designed to train the GPT-3.5-turbo on custom data sets, which could fuel discussions around proprietary AI systems and open-source AI models.
- The article also touches on the ongoing GPU shortage, particularly NVIDIA's H100 chips, and the announcement of NVIDIA's next generation of GPUs, the GH200, which offers 141 GB of RAM.
- There are ongoing legal issues around the use of LLMs and generative AI in relation to copyright laws. The article highlights recent lawsuits against Meta and OpenAI, and discusses the concept of "fair use" and how it might apply to the training of machine learning models.