

1
Feature Story
NLP Research in the Era of LLMs
Dec 22, 2023 · nlpnewsletter.substack.com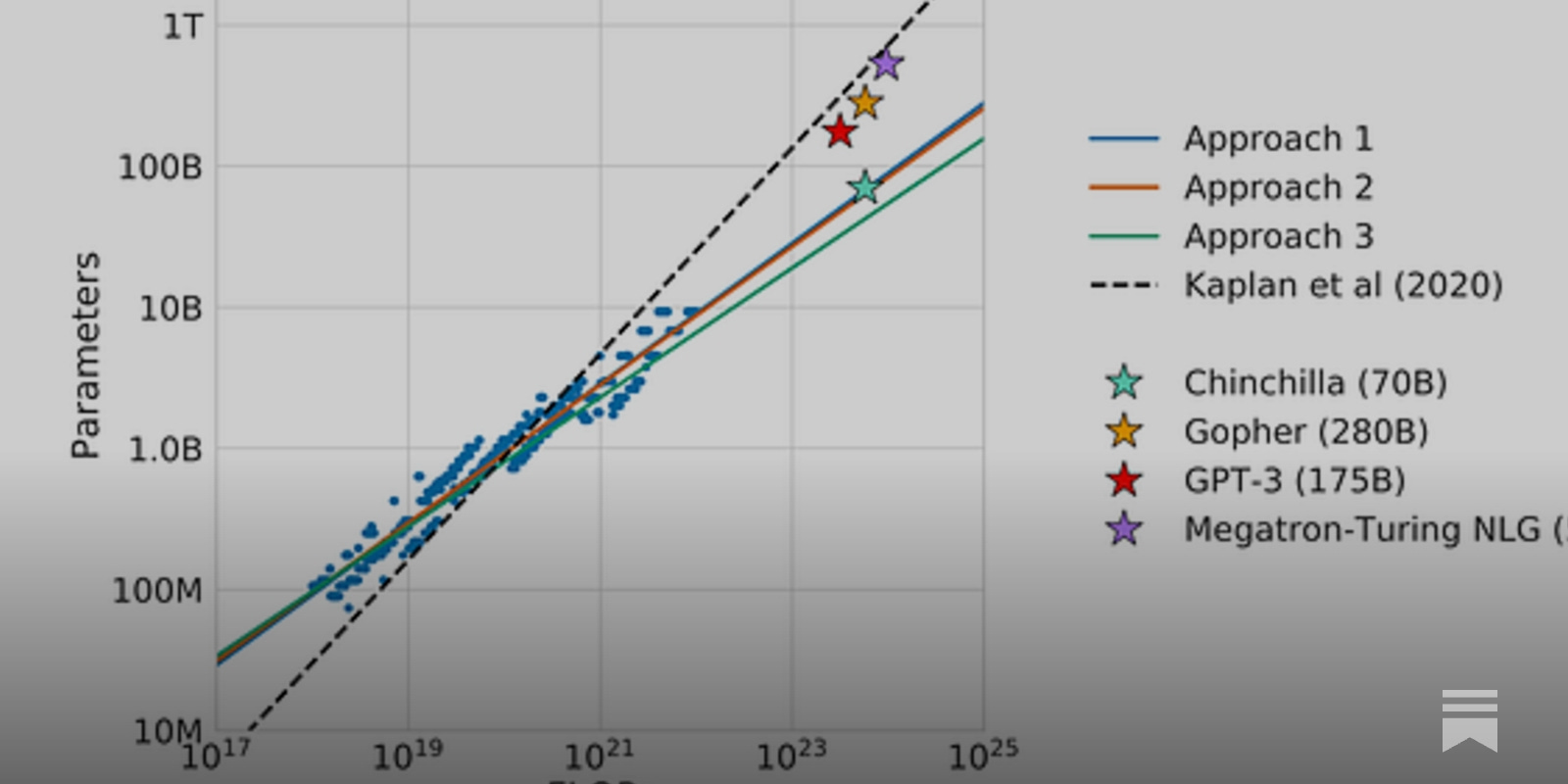
The author emphasizes that while massive compute often achieves breakthrough results, it is often inefficient and over time, improved hardware, new techniques, and novel insights provide opportunities for dramatic compute reduction. The article also suggests that academic researchers can develop new methods that, after small-scale validation, are shared with the community for further experimentation and scaling up. The author concludes by encouraging researchers to look beyond standard NLP tasks and be ambitious in their research endeavors.
Key takeaways
- The current state of Natural Language Processing (NLP) research is not as bleak as it seems despite the high computational requirements of large language models (LLMs). There are several research directions that do not require much compute.
- Efficiency in LLMs can be improved by considering the entire LLM stack, including data collection and preprocessing, model input, model architecture, training, downstream task adaptation, inference, data annotation, and evaluation.
- Research in small-scale regimes, analysis and model understanding, and intrinsically small-scale settings due to data constraints can be valuable in the era of LLMs.
- There is a need for reliable means to evaluate LLMs, especially as applications become more complex. Existing automatic metrics are ill-suited for complex downstream applications and open-ended natural language generation tasks.