

1
Feature Story
OpenCoder: A True Open-Source Approach to Code LLMs
Nov 11, 2024 · medium.com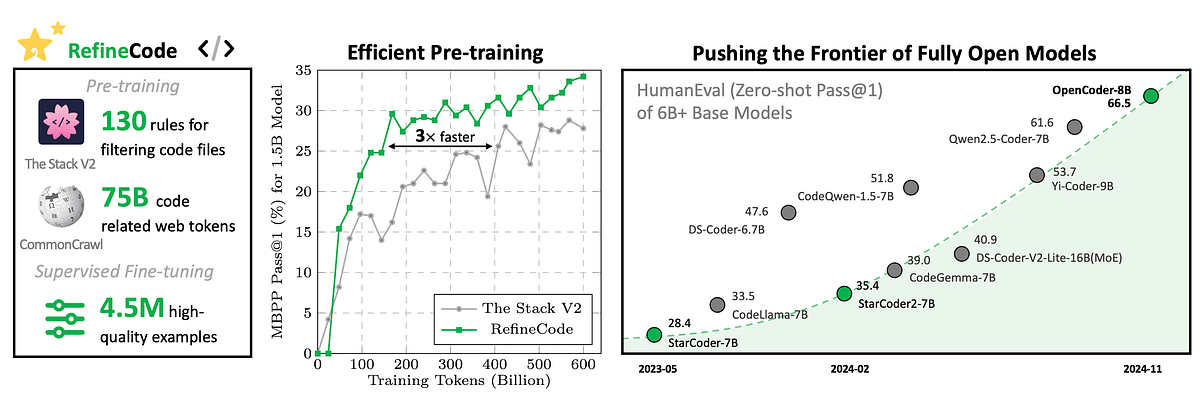
OpenCoder consists of two models: a smaller 1.5 billion parameter model and a larger 8 billion parameter model. It is trained on 2.5 trillion tokens, with 90% raw code and 10% code-related web data. Unlike proprietary models, OpenCoder does not keep its methods or results behind closed doors. The full release includes model weights and inference code, reproducible training data, a transparent data processing pipeline, and experimental results of ablation studies.
Key takeaways
- OpenCoder is an open and reproducible Large Language Model (LLM) specifically trained to understand and generate programming code.
- It is fully transparent and aims to match the performance of top-tier proprietary and Open Source models.
- OpenCoder comprises two models: a smaller 1.5 billion parameter model and a larger 8 billion parameter model, trained on 2.5 trillion tokens.
- The full release of OpenCoder includes model weights and inference code, reproducible training data, a transparent data processing pipeline, and experimental results of ablation studies.