

1
Feature Story
picoLLM — Towards Optimal LLM Quantization
May 30, 2024 · picovoice.ai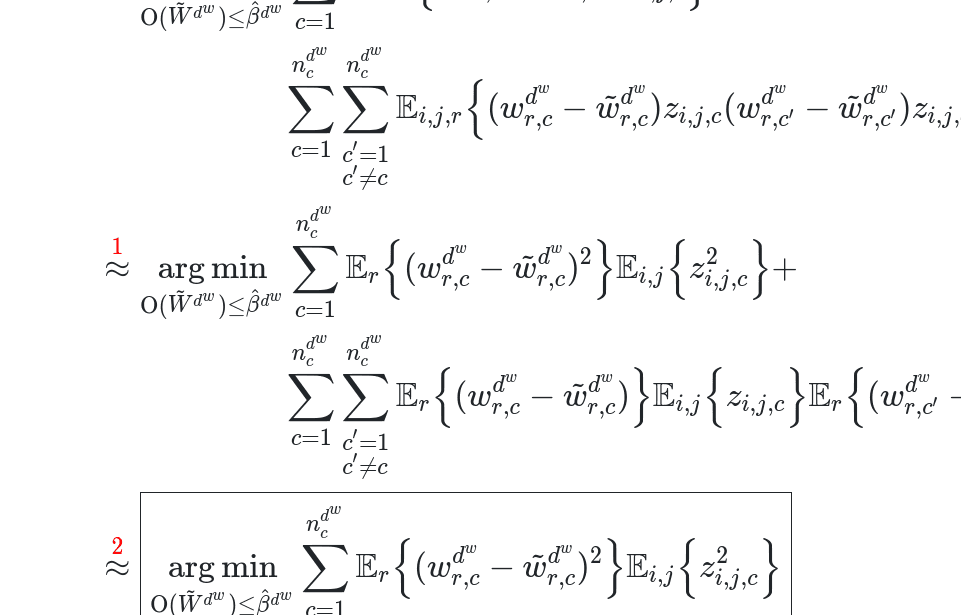
The picoLLM Compression algorithm is presented in a top-down manner, discussing inter-functional bit allocation and intra-functional allocation. The article also presents benchmarking results to support the efficacy of the picoLLM Compression algorithm, comparing it with the widely adopted GPTQ. The benchmarks include six different LLMs and three tasks: MMLU (5-shot), ARC (0-shot), and Perplexity. The article concludes by inviting developers to start building with picoLLM, which is free for open-weight models, and announcing support for more LLM families in the future.
Key takeaways
- picoLLM Compression is a new large language model (LLM) quantization algorithm developed by Picovoice. It learns the optimal bit allocation strategy across and within LLM's weights, unlike existing techniques that require a fixed bit allocation scheme.
- picoLLM Compression comes with the picoLLM Inference Engine, which runs on various platforms including CPU, GPU, Linux, macOS, Windows, Raspberry Pi, Android, iOS, Chrome, Safari, Edge, and Firefox. It supports open-weight models such as Gemma, Llama, Mistral, Mixtral, and Phi.
- When applied to Llama-3-8b, picoLLM Compression recovers MMLU score degradation of the widely adopted GPTQ by 91%, 99%, and 100% at 2, 3, and 4-bit settings. This suggests that picoLLM Compression is effective across different LLM architectures.
- Picovoice is planning to support more LLM families in the future. picoLLM is free for open-weight models and developers can start building with it without needing to talk to a salesperson or provide a credit card information.