

1
Feature Story
Refusal in LLMs is mediated by a single direction
May 03, 2024 · news.bensbites.com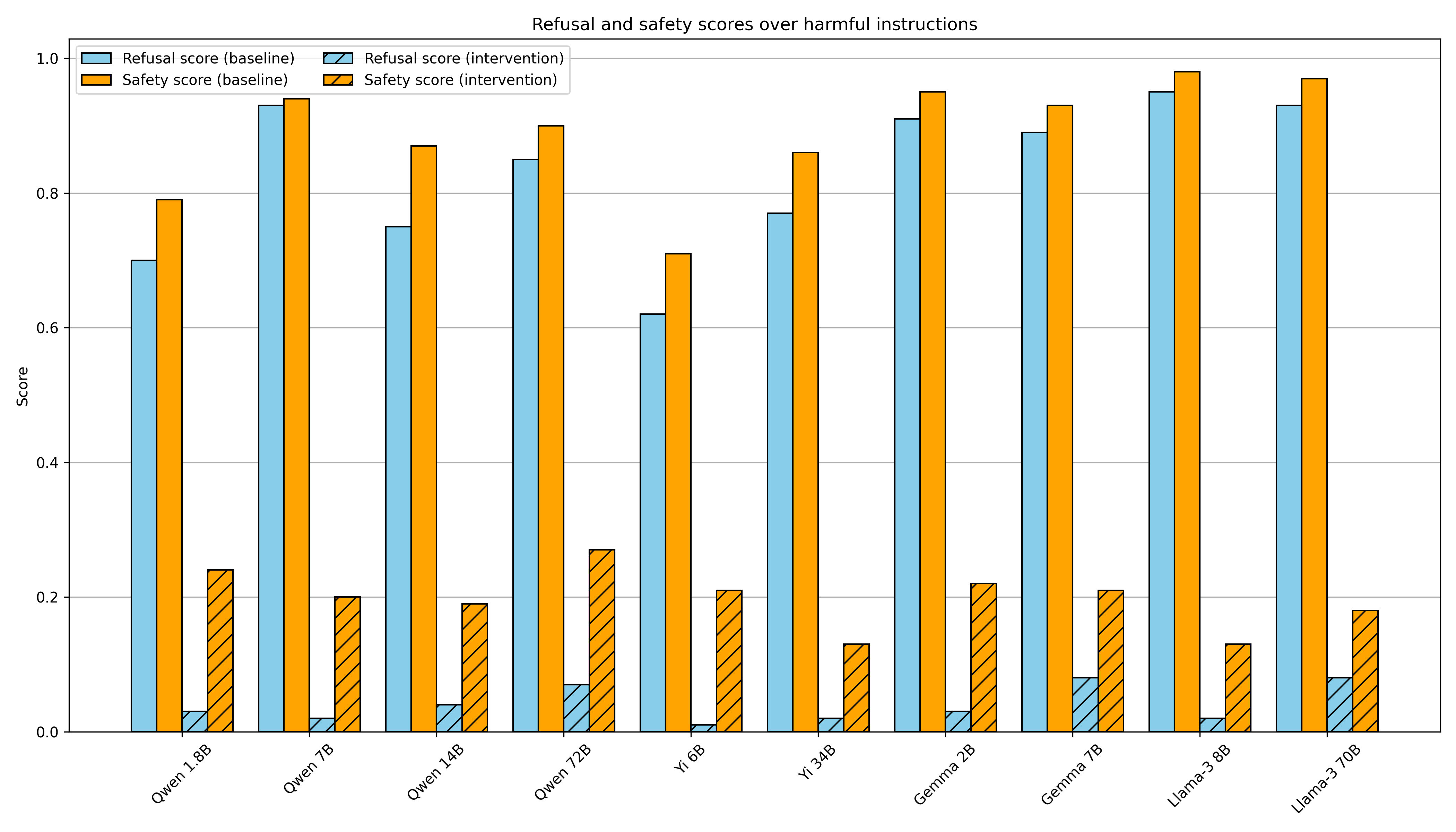
The researchers also explored the concept of refusal as a progression of features, evolving from embedding space, through intermediate features, to unembed space. They hypothesized that a single intermediate feature is instrumental in the model’s refusal. The study provides strong evidence that refusal is represented as a one-dimensional linear subspace within the activation space. However, the researchers acknowledge limitations in their understanding of how the "refusal direction" is computed from harmful input text or translated into refusal output text.
Key takeaways
- The study found that refusal in AI models is mediated by a single direction in the residual stream, meaning that preventing the model from representing this direction hinders its ability to refuse requests, and artificially adding in this direction causes the model to refuse harmless requests.
- This phenomenon holds across open-source model families and model scales, leading to a simple modification of the model weights that effectively jailbreaks the model without requiring any fine-tuning or inference-time interventions.
- The researchers used a simple methodology to extract the "refusal direction" and found that removing this direction blocks refusal, and adding in this direction induces refusal.
- While the study provides important insights into how refusal is implemented in chat models, the researchers acknowledge that they still do not fully understand how the "refusal direction" gets computed from harmful input text, or how it gets translated into refusal output text.