

1
Feature Story
Researchers discover explicit registers eliminate vision transformer attention spikes
Oct 01, 2023 · notes.aimodels.fyi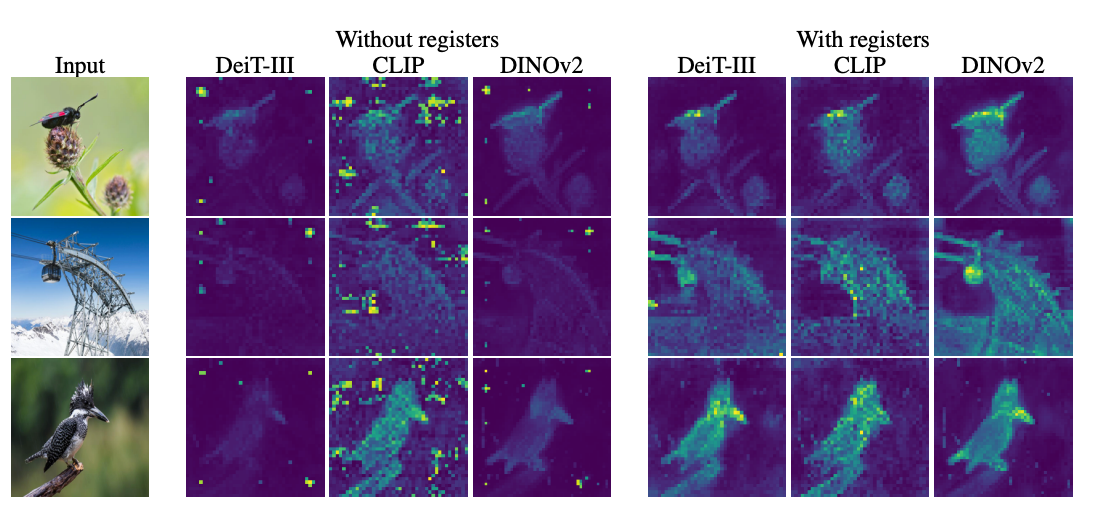
To address this issue, the researchers proposed the addition of "register" tokens to the sequence, providing temporary storage for internal computations and preventing the hijacking of random patch embeddings. This simple tweak resulted in smoother, more semantically meaningful attention maps, minor performance boosts on various benchmarks, and improved object discovery abilities. The study highlights the importance of understanding the inner workings of neural networks to guide incremental improvements.
Key takeaways
- Researchers have discovered that Vision Transformers (ViTs) often focus on unimportant background elements in images, due to a small fraction of patch tokens having abnormally high L2 norms.
- The authors of the study hypothesize that these high-norm tokens are used by the model to store temporary global information about the full image, a process they refer to as "recycling".
- To prevent this recycling process from hijacking random patch embeddings, the researchers propose adding "register" tokens to the sequence, providing temporary storage for internal computations.
- This simple fix not only improves the attention maps of the models, but also boosts performance on various benchmarks and greatly improves object discovery abilities.