

1
Feature Story
Snapchat used AI agents to build a sound-aware video captioning system
Mar 02, 2024 · aimodels.substack.com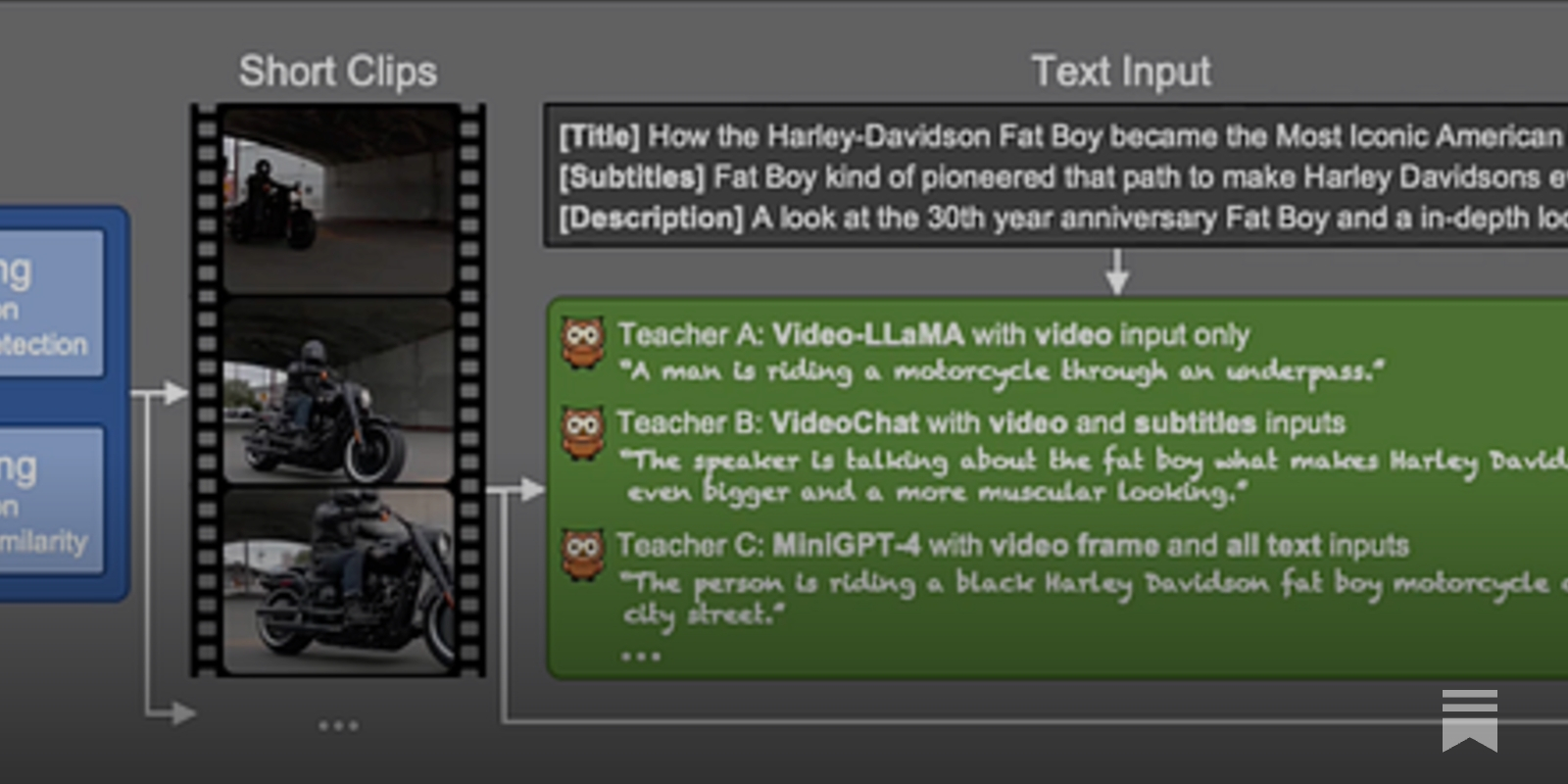
Panda-70M is a breakthrough in large-scale video-and-language data and provides a blueprint for assembling even larger datasets through cross-modality learning. Despite its limitations, such as the need for more diverse video content and manual verification of automatically generated captions, it is a crucial resource for training future multimodal AI systems. The dataset represents a significant step towards artificial general intelligence that can comprehend the world in the same way humans do.
Key takeaways
- Researchers from Snap, UC Merced, and the University of Trento have developed Panda-70M, a dataset providing 70 million high-resolution YouTube video clips paired with descriptive captions, to aid in the training of AI systems for understanding video content.
- Panda-70M was created using an automated captioning pipeline powered by cross-modality teacher AI models, which generated multiple captions for each video clip.
- Pre-training on Panda-70M significantly improved AI video comprehension skills, with gains seen in video captioning relevance and accuracy, text-to-video retrieval performance, and video reconstruction error rate.
- While Panda-70M is a breakthrough in large-scale video-and-language data, the researchers acknowledge areas for further expansion, including adding more diverse video content, increasing caption density, manual verification of automatically generated captions, and scaling up to billions of clips.