

1
Feature Story
The lifecycle of a code AI completion
Apr 07, 2024 · sourcegraph.com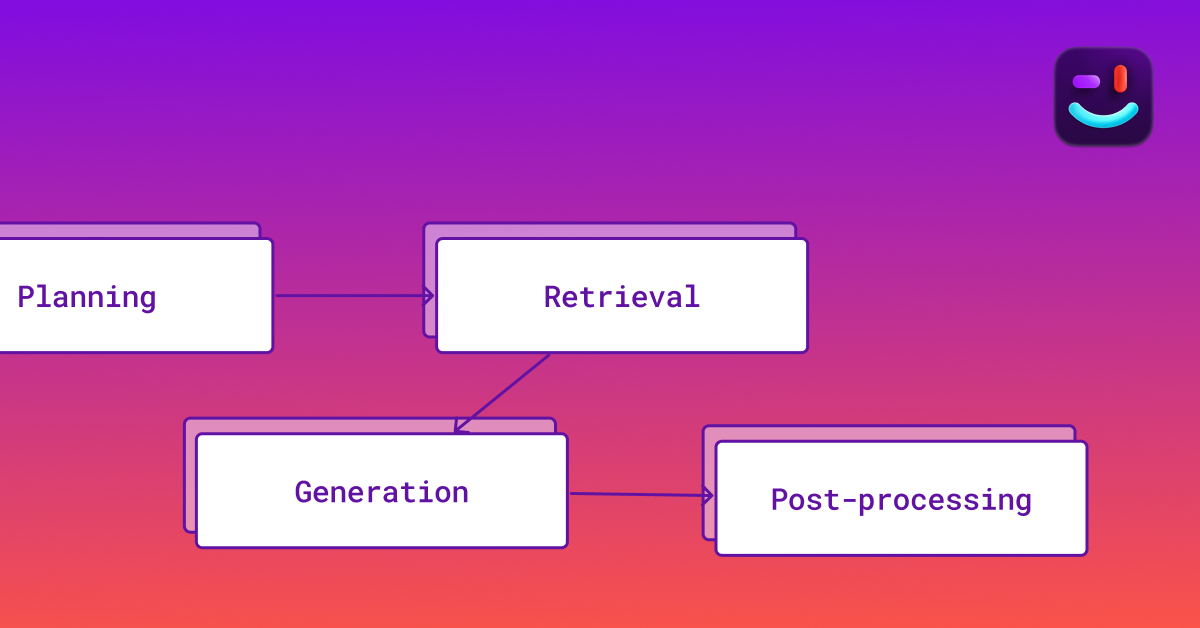
The planning phase involves preparing the best execution plan for the autocomplete request, while the retrieval phase involves gathering relevant context for the current problem. The generation phase is where the LLM generates a completion that is relevant, accurate, and fast. Lastly, the post-processing phase involves processing the generated content to ensure it fits well into the existing document. The article also discusses the challenges and improvements made to reduce latency and improve the quality of the autocomplete results.
Key takeaways
- Generative AI, such as Cody, uses a Large Language Model (LLM) to generate code AI responses. This process involves various pre and post processing steps, understanding the role of context, and more.
- Code autocomplete requests take the current code inside the editor and ask an LLM to complete it. This process involves understanding the user's position in the code and the context of the codebase.
- Improving AI completions involves understanding the task at hand, extracting relevant context, and using retrieval augmented generation (RAG) to retrieve specific knowledge from external sources.
- Improvements to the Large Language Model (LLM) used in autocomplete processes can significantly enhance the quality and speed of code completions. This includes changes to the prompt, support for "Fill in the Middle", and efforts to reduce latency.