

1
Feature Story
Tool-Integrated Reasoning: A New Approach for Math-Savvy LLMs
Oct 02, 2023 · notes.aimodels.fyi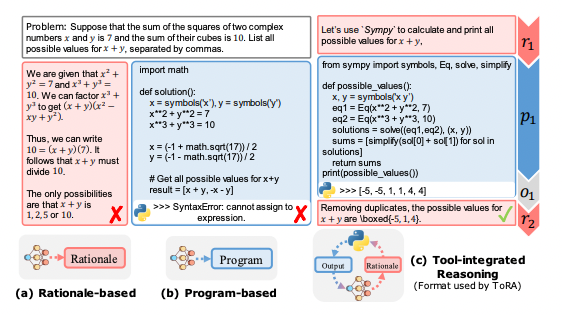
The TORA models were systematically evaluated on 10 diverse mathematical reasoning datasets and showed substantial gains across model sizes and tasks. TORA models achieved 13-19% higher accuracy on average compared to the best existing open-source models. On a challenging competition-level math test, TORA-7B scored 40% accuracy, beating the previous best model by 22 percentage points absolute. TORA-34B attained 51% accuracy on MATH, surpassing GPT-4's performance of 43% on the same problems. Despite these improvements, the researchers identified geometry and advanced algebra as areas where models still struggled, indicating room for further improvement.
Key takeaways
- Researchers from Tsinghua University and Microsoft have made progress in improving the mathematical reasoning skills of large language models by integrating external mathematical tools into the models' reasoning process.
- The researchers created a dataset demonstrating tool-integrated reasoning on math problems and trained models to predict tool usage behavior and natural language rationales demonstrated in the dataset, producing a series of Tool-Integrated Open-source Reasoning Agents (TORA).
- The TORA models showed significant performance improvements on diverse mathematical reasoning datasets, achieving 13-19% higher accuracy on average compared to existing models and up to 51% accuracy on a challenging math test.
- Despite the improvements, challenges remain in areas like geometry and advanced algebra, indicating the need for advances in multi-modal reasoning, tighter integration with graphical libraries, and stronger symbolic reasoning capabilities.