

1
Feature Story
Effort Engine
Apr 17, 2024 · kolinko.github.io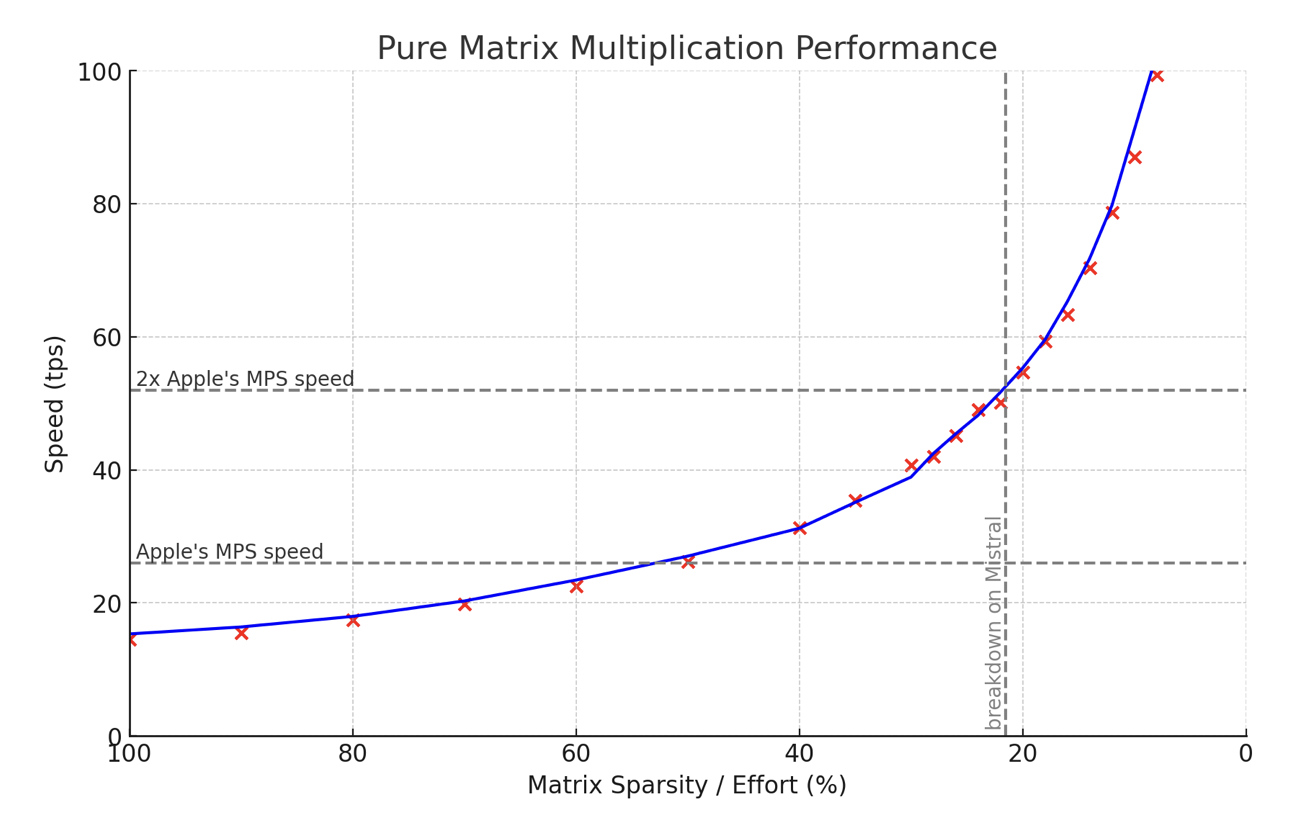
The implementation is currently done for FP16 only and while the multiplications are fast, inference is still slightly lacking due to the need for improvement in some non-essential parts. The algorithm also allows users to dynamically decide how much of the model to load into memory, essentially skipping the least important weights while loading. Despite some implementation overhead, the initial results seem robust enough to warrant publication. The author encourages readers to test the 0.0.1B version of the algorithm and provides a deep dive into its workings.
Key takeaways
- A new algorithm for LLM Inference allows for adjustable calculation effort in real time, with the ability to skip loading the least important weights.
- The algorithm is implemented for Mistral and should work for all other models without retraining, only requiring conversion to a different format and some precomputation.
- The implementation allows for dynamic decision-making on how much of the model to load into memory, essentially allowing for ad-hoc distillation.
- While the algorithm is fast, there is still room for improvement in non-essential parts like softmax, and help from a Swift/Metal engineer is sought to fix implementation overhead issues.